前情提要: 昨天透過umap將bert embedding做圖示化,這種模型都是經過大量資料訓練而來,才會有這麼好的效果。
昨天提到了文字方面的模型,今天來提提聲音方面的模型吧。
參考: https://blog.csdn.net/qq_40168949/article/details/128677418
wavlm論文: https://arxiv.org/pdf/2110.13900
有幾個模型wav2vec 2, hubert, wavlm,這些都是用"無標籤"的聲音訓練出來的,所以訓練完的model本身不能直接拿來使用,跟bert一樣需要再用特定資料訓練特定場景,可應用的downstream task
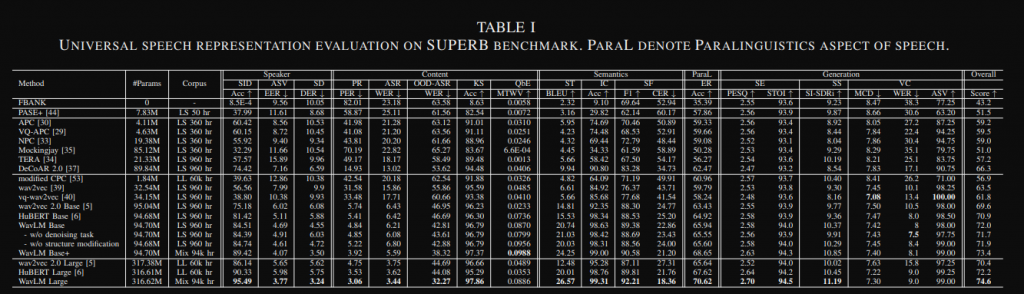
Speaker Identification (SID), Automatic Speaker Verification (ASV), Speaker Diarization (SD),
Phoneme Recognition (PR), Automatic Speech Recognition
(ASR), Keyword Spotting (KS),
Speech Translation (ST)
Emotion Recognition (ER),
Speech Enhancement (SE), Speech Separation (SS) and Voice
Conversion (VC).
主要會分成以上這幾種,基本上應用的場景很多,我自己本身是有做過情緒辨識效果上還不錯。
這裡透過這個例子來看看如何使用吧~
參考: https://github.com/m3hrdadfi/soxan
流程圖(參考圖片: https://www.semanticscholar.org/reader/f1eb9232314480050400fe52abd75f128da7cc86 )
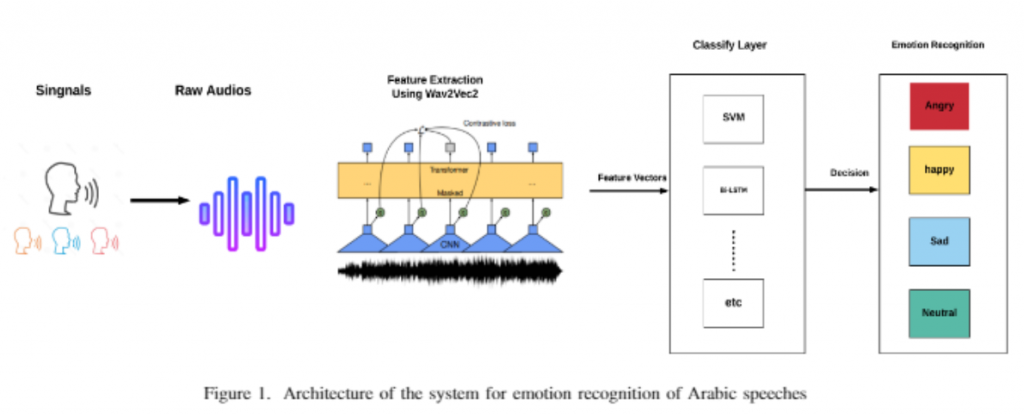
上面github的colab程式片段: https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb#scrollTo=Fv62ShDsH5DZ
MLP其實就是多個nn.Linear組合合成,在我們之前範例也有運用過,那這個範例透過transformers來呼叫wav2vec2,甚至現在可以透過torchaudio來直接呼叫 (https://pytorch.org/audio/main/generated/torchaudio.pipelines.Wav2Vec2Bundle.html#torchaudio.pipelines.Wav2Vec2Bundle ),就可以抽取出embedding囉
import torch
import torch.nn as nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from transformers.models.wav2vec2.modeling_wav2vec2 import (
Wav2Vec2PreTrainedModel,
Wav2Vec2Model
)
class Wav2Vec2ClassificationHead(nn.Module):
"""Head for wav2vec classification task."""
# 使用MLP來分類
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.final_dropout)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, features, **kwargs):
x = features
x = self.dropout(x)
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
class Wav2Vec2ForSpeechClassification(Wav2Vec2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.pooling_mode = config.pooling_mode
self.config = config
self.wav2vec2 = Wav2Vec2Model(config) # 呼叫transformers的模型
self.classifier = Wav2Vec2ClassificationHead(config) # MLP
self.init_weights()
def freeze_feature_extractor(self):
self.wav2vec2.feature_extractor._freeze_parameters()
def merged_strategy(
self,
hidden_states,
mode="mean"
):
if mode == "mean":
outputs = torch.mean(hidden_states, dim=1)
elif mode == "sum":
outputs = torch.sum(hidden_states, dim=1)
elif mode == "max":
outputs = torch.max(hidden_states, dim=1)[0]
else:
raise Exception(
"The pooling method hasn't been defined! Your pooling mode must be one of these ['mean', 'sum', 'max']")
return outputs
def forward(
self,
input_values,
attention_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
labels=None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.wav2vec2(
input_values,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
hidden_states = self.merged_strategy(hidden_states, mode=self.pooling_mode)
logits = self.classifier(hidden_states)
這裡只是透過範例來講解怎麼用,如果實際想訓練可以直接用他的github,但因為是三年前了,可能有些程式會有問題。
在聲音方面也有這種大型的pre-trained model,另外目前比較常看到的是用wavlm加進TTS,讓你能用5~30s的聲音來zero-shot出你的聲音,不然ASR的部分基本上會用whisper,比較少在用這幾個了,不過做為學習可以用這個當出發點。
另外就是為甚麼需要大型的pre-trained model,在做情緒辨識和一些專案我體驗蠻多的,最主要就是減少overfitting,因為他們已經拿了大量資料來訓練,已經看過各個場景,那你透過downstream讓他focus在某個場景,可以想像他已經有很多經驗,所以用這些經驗來判斷效果當然比較好。
這兩天都沒有談論本身model細節,我認為先會拿來使用比較重要,等到累積的經驗夠了,或哪天你需要做這塊,那就再去研究即可。
今天就先到這裡囉~


 iThome鐵人賽
iThome鐵人賽